
Designing with Metadata
What is this course about?
Metadata is what makes content findable, connectable, and usable at scale. But most people working with content systems, knowledge bases, and digital assets inherit metadata that was never designed on purpose. Fields are vague. Values are inconsistent. Nobody agrees on what "subject" means. Things get tagged differently by different people. And nobody can find what they're looking for.
This course is about fixing that. We cover what metadata actually is, why it breaks down in practice, and how to make deliberate design decisions that hold up over time. Whether you're building a new schema from scratch or auditing a broken one, this course gives you the tools and vocabulary to do it well.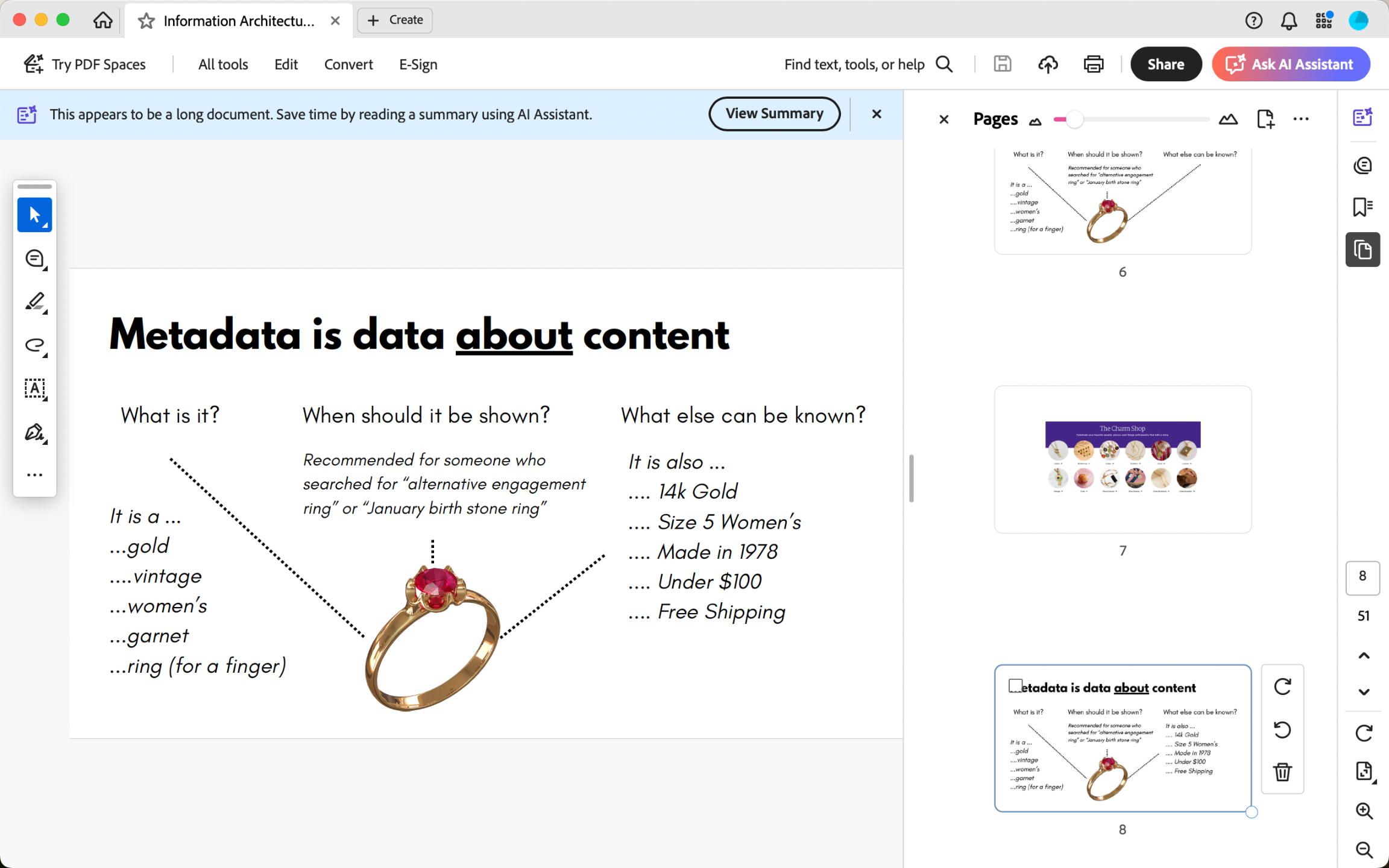 Course Example Slide 1
Course Example Slide 1
What is the learning objective of this course?
By the end of this course you will be able to design, audit, and govern metadata schemas that actually work in practice.
That means you'll be able to:
- Explain the five types of metadata and identify which type applies in any given situation
- Choose between manual, automated, and hybrid approaches to metadata creation, and defend that choice
- Audit an existing metadata schema and spot the specific design decisions causing it to fail
- Design a schema that balances required and optional fields, controlled and uncontrolled values, and progressive disclosure
- Apply established metadata standards like Dublin Core and Schema.org instead of building something from scratch
- Write metadata governance recommendations that stakeholders can actually act on
 Course Example Slide 2
Course Example Slide 2
How is this course taught?
- One workshop recording, approximately 90 minutes, taught live by Abby Covert
- Full slide deck from the live session, available to download and keep
- Two case study walkthroughs with worked examples: an over-engineered legal document repository and a university library's "everything schema"
- A group exercise reviewing and redesigning a real broken schema, worked through on camera
- A peer practice exercise where participants work through schema redesign together
- Part of the IA in Practice series, connecting directly to adjacent courses on controlled vocabularies, taxonomies, and information architecture auditing
 Course Example Slide 3
Course Example Slide 3
Who was this course designed for?
- You manage or contribute to a content management system, knowledge base, digital asset library, or data catalog
- You've inherited metadata that no one designed on purpose and you're not sure how to fix it
- You've tried to search for something in your own systems and couldn't find it
- Your title might be librarian, archivist, content strategist, information architect, knowledge manager, data steward, UX researcher, or just "the person who keeps things organized"
- You think in systems, notice when things aren't labeled consistently, and feel the downstream cost when nobody else does
- You want to go deeper than tools and understand the principles behind why metadata works or fails
- You've been doing this kind of structural work for years under other names, and you want the vocabulary to match
- You want to make better decisions about governance, not just better spreadsheets
Course Outline
What is Metadata?
A grounded introduction to what metadata is and isn't, using real examples to show how descriptive, structural, administrative, technical, and preservation metadata each serve different purposes.
Use Cases and Types
A look at where metadata problems show up most often: content management, data governance, search and discovery, asset management, and compliance. Learn to recognize which type of metadata is doing the work in each case.
Approaches to Metadata Creation
The tradeoffs between manual, automated, and hybrid approaches. When human judgment is worth the cost, when software can do the heavy lifting, and how to combine both without creating a bottleneck.
Standards, Languages, and Building Blocks
Why leaning on existing standards like Dublin Core and Schema.org saves time and earns trust. A practical overview of the languages metadata is written in and the core concepts (element, value, scheme, schema, syntax) every practitioner needs to know.
Lessons Learned
Design principles drawn from real projects: provenance, progressive disclosure, future-proofing, and when free text creates more problems than it solves.
Case Study: The Over-Engineered Repository
A walkthrough of a 28-field legal document schema that was failing in practice, and a step-by-step look at how to diagnose and redesign it.
Case Study: The Everything Schema
A university library tried to build one schema for all digital assets. It didn't work. We look at why, and what a better approach would ask and answer before designing anything.

Who is guiding this course?
"Metadata is where the work of information architecture becomes invisible, and also where it becomes most consequential. This course is about making those decisions visible and intentional." — Abby Covert
A community organizer, information architect and sensemakers with twenty years experience helping others make the unclear, clear.
